

Is There Really Only One Way to Implement Caching for APIs?

Caching involves storing duplicates of frequently accessed data at various points along the request-response path.
When a consumer seeks a resource like a Youtube video, the request traverses one or more caches (local cache, proxy cache, or reverse proxy) towards the service hosting the resource.
If any cache along the path has a recent copy, it fulfills the request; otherwise, the request proceeds to the origin server.
This process defines two key states:
Cache Hit: Data requested is found in the cache memory, accelerating delivery to the processor.
Cache Miss: The requested data is absent in the cache, causing delays as the program fetches it from higher cache levels or the main memory.
But it there really a single way to implement caching?
Cache-Aside Pattern (Lazy Loading)
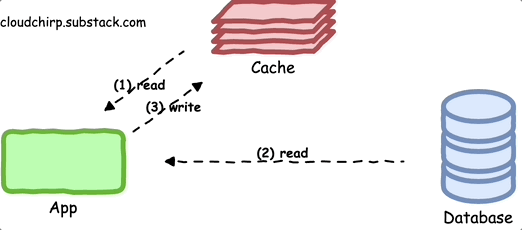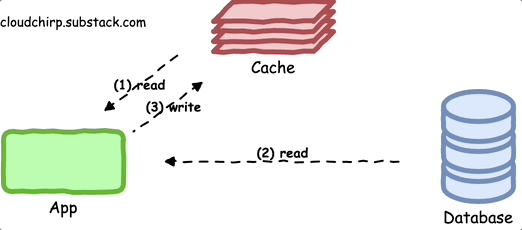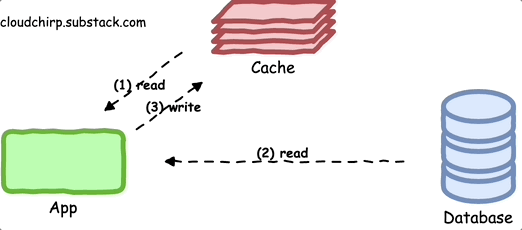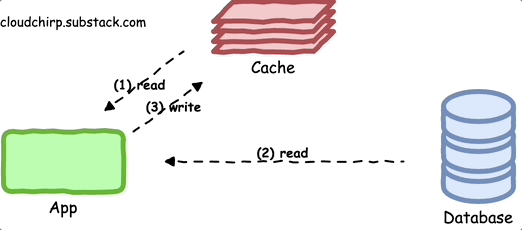
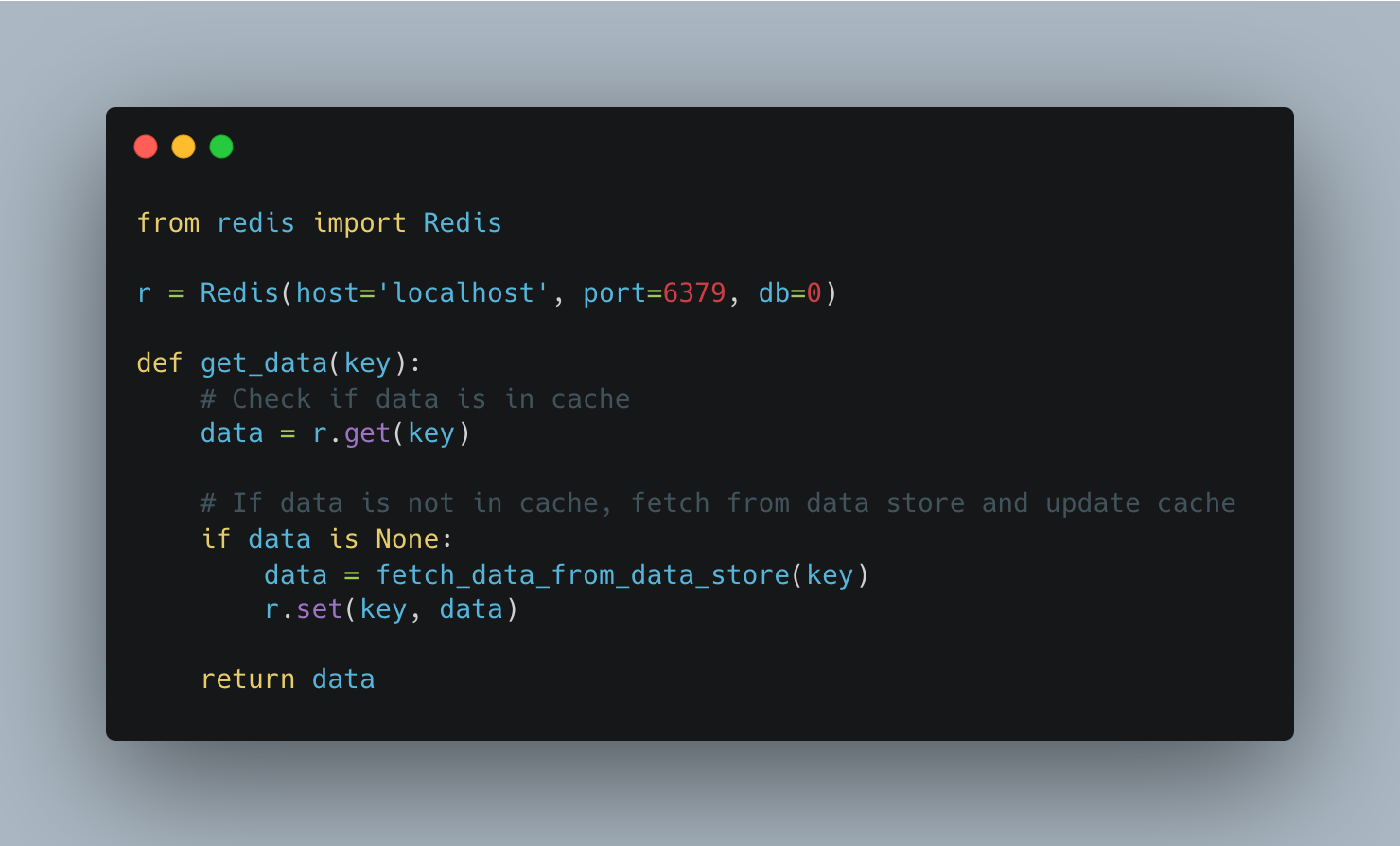
The cache-aside pattern is one of the most commonly used caching approaches.
In this pattern, the application:
Initially requests data from the cache.
If the data is not in the cache, the application fetches it from the primary data store and updates the cache before providing the data back to the caller.
Here's an example using Redis in Python:
Advantages
Easy implementation
Low read latency for frequently accessed data
Disadvantages
High read latency on a cache miss
Potential data inconsistency — Data in cache is not updated
Use Cases
Read-heavy workloads
Data inconsistency is acceptable
Read-Through Pattern
In the read-through pattern, the cache is responsible for retrieving data from the primary data store in the event of a cache miss.
In this approach client only interacts with the cache, eliminating the need for explicit handling of cache misses.
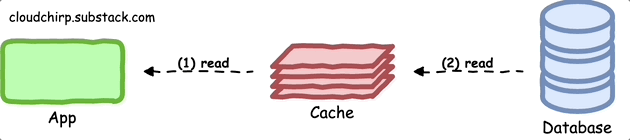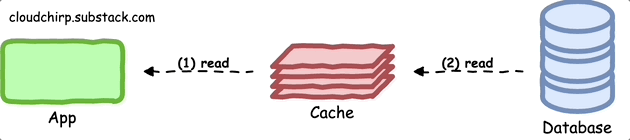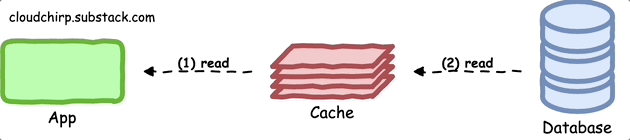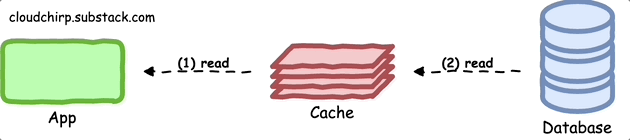
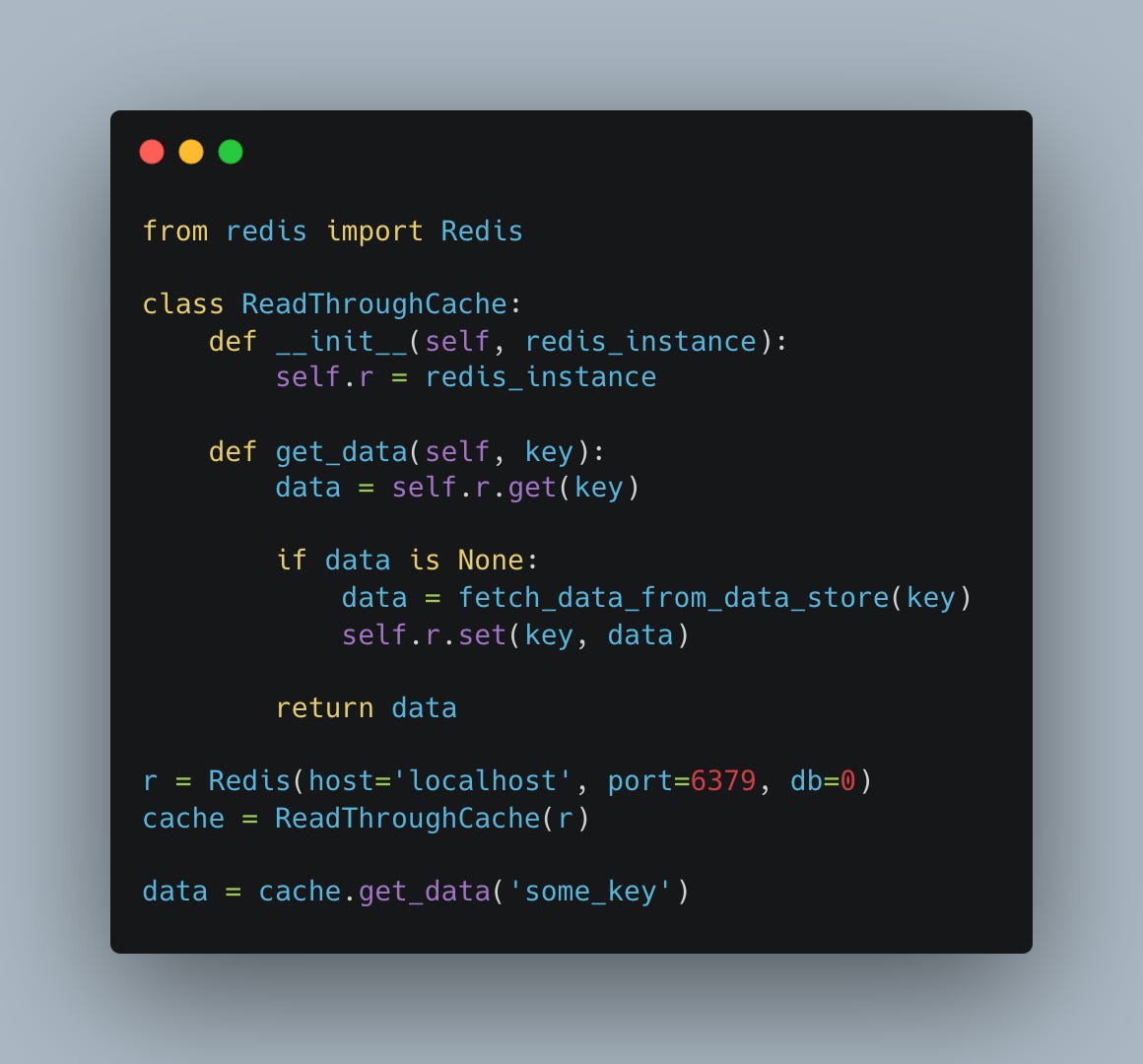
To implement the read-through pattern using Redis, you can use a custom cache implementation that fetches the data from the primary data store when necessary:
Advantages
Easy use — only interact with cache
Low read latency for frequently accessed data
Disadvantages
High read latency on a cache miss
Potential data inconsistency — Data in cache is not updated
Use Cases
Read-heavy workloads
Data inconsistency is acceptable
Write-Through Pattern
With this pattern, the application writes data to both the cache and the primary data store, ensuring that the cache consistently reflects the most recent data.
This pattern minimizes the likelihood of stale data within the cache.
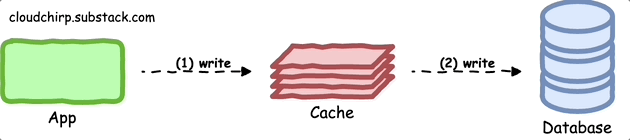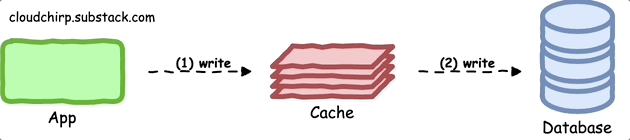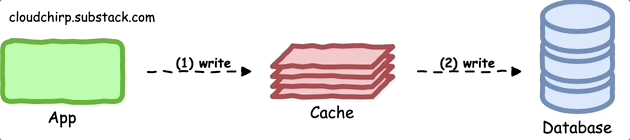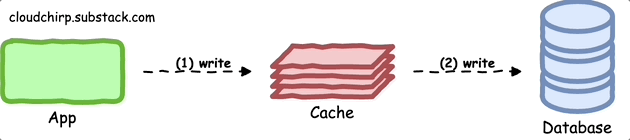
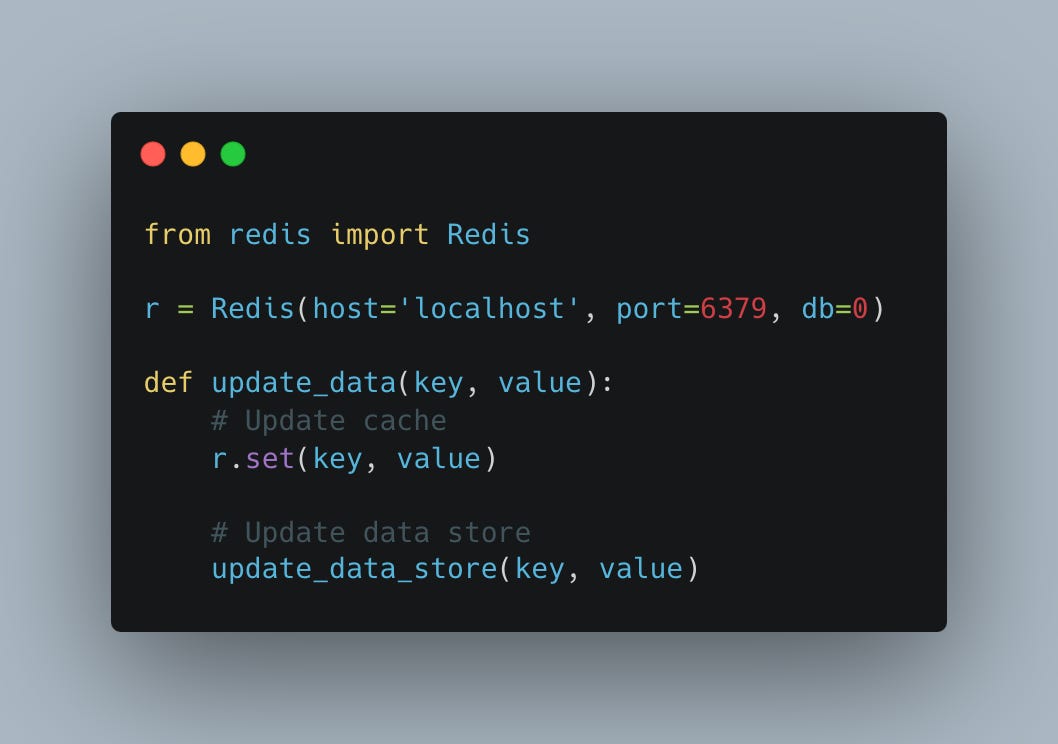
Here's an example of how you can implement the write-through pattern with Redis in Python:
Advantages
Data consistency — cache always contains fresh data
Low read latency
Disadvantages
Most data in the cache is never read
High write latency — both cache and database need to be updated
Use Cases
A low number of writes expected
Data freshness is important
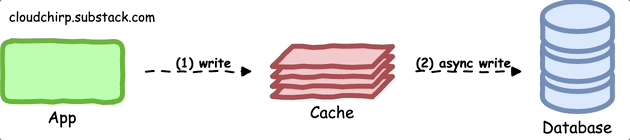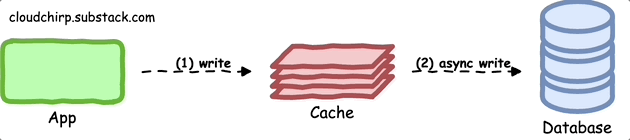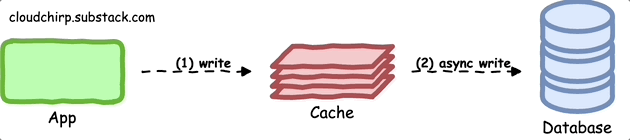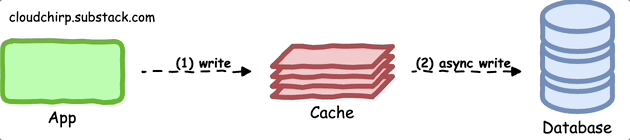
Write-Behind Pattern
The write-behind pattern is an optimization of the write-through pattern.
In this pattern, the application writes data to the cache and asynchronously updates the primary data store.
This improves the application's write performance, as it does not need to wait for the primary data store to acknowledge the write operation.
To implement the write-behind pattern, you can use a message queue or a background worker to handle the asynchronous updates:
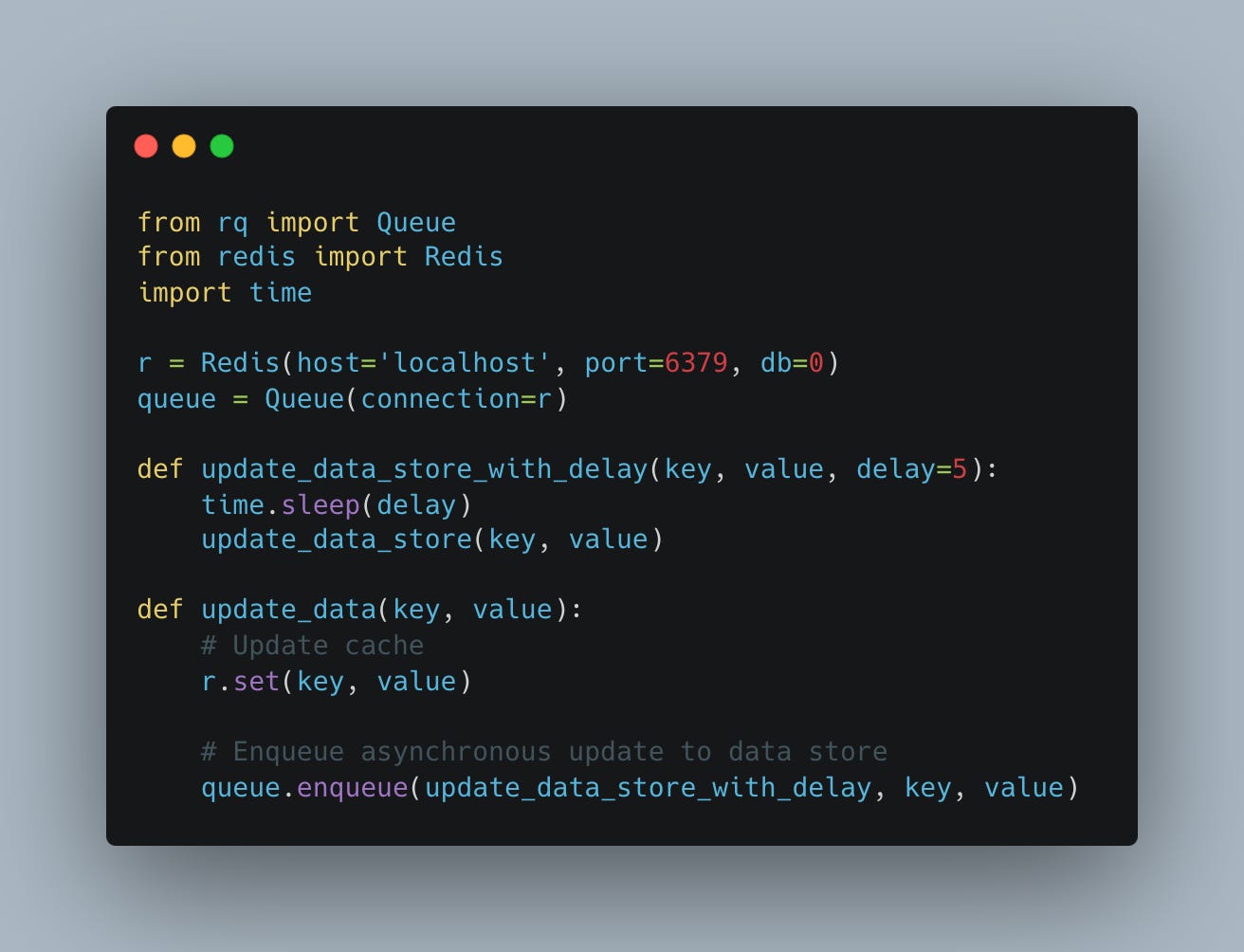
Advantages
Easy use — only interact with cache
Low write latency — cache updated asynchronously
Disadvantages
Complex implementation
Increased risk of data loss — cache might fail before writing to the database
Use Cases
Write-heavy workloads
Loss of data is not critical
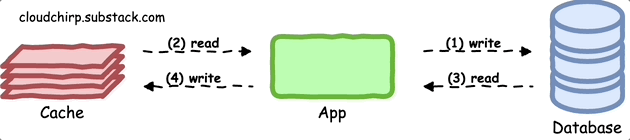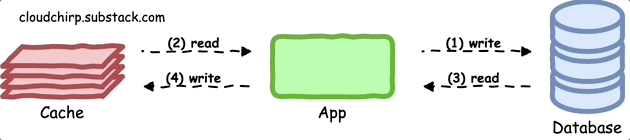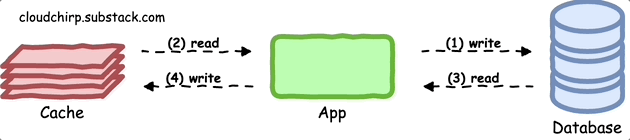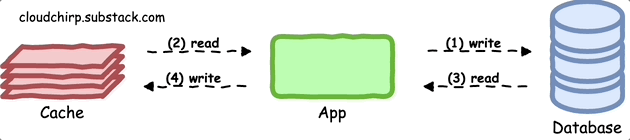
Write-Around Pattern
In this pattern, when the user requests to store the data, the application:
First writes data to the primary data store.
Then when data is requested, application initially checks the cache.
In case of cache miss, the application fetches it from the primary data store and updates the cache before providing the data back to the caller.
Here's an example of how you can implement the write-around pattern with Redis in Python:
Advantages
Reduced risk of data loss
Reduced cache pollution — cache only stores frequently accessed data
Disadvantages
High read latency on a cache miss
Potential data inconsistency — Data in cache is not updated
Use Cases
(Re)Read- and Write-heavy workloads
A high cache miss rate is acceptable
💡 In production environments, the data storage and retrieval techniques vary according to the application requirements and often the combination of two or more is used.
⏪ Did you miss the previous issues? I'm sure you wouldn't, but JUST in case:


I hope you find these resources useful. Stay tuned for more exciting developments and updates in the world of cloud infrastructure in next week's newsletter.
Until then, keep ☁️-ing!
Warm regards, Teodor