



Lessons from Scaling Terraform Code Across Teams, Environments, and Cloud Providers
Terraform from Zero to Scale

As an SRE, I’ve had the privilege of managing various infrastructures that scaled from serving just 10 developers or users to hundreds, even thousands.
At every stage of that growth, the requirements changed—and so did the opinions on how the infrastructure-as-code (IaC) repository should be structured.
Yet no matter how the Terraform code was initially organized, it always evolved toward the same pattern: a structure that made it easier to manage as complexity increased and one that made the most of the automation tools powering it.
In every startup I’ve been part of, we almost always started with a single Terraform file—a monolith, if you will.
Some might say that’s a flawed approach from the start. But in the early days, speed often outweighs sustainability. You’re focused on shipping, not on long-term infrastructure “hygiene”.
And usually, there’s just one person managing the infrastructure. Every other developer has full access to the code, there are no separate environments (like staging or production), and going multi-cloud isn’t even on the radar.
And that’s perfectly fine—for a while.
But then things start to change. Terraform plans and applies take longer than you’d like. A new infrastructure engineer joins, and now you have to figure out how to safely share the state file. Then come the questions like—how can other developers, especially those less familiar with infrastructure, self-serve the infrastructure without breaking things?
If you’ve been down this path, you know exactly what I mean.
Rather than listing every growing pain, let’s focus on something more useful: how to structure your infrastructure code from the start in a way that scales—with a pattern that actually works.
Some of this is subjective, sure. But I’ll try to give you enough objective reasons to show why adopting this pattern makes sense.
Terraform Child Modules and Where Should you Place them
There’s not much science fiction when it comes to Terraform modules—pretty much every tutorial out there recommends putting reusable infrastructure code into a /modules folder.
How you organize the individual modules inside this folder doesn’t really matter too much, as long as it’s intuitive for the people using them to know where (at what relative path) to find what they need.
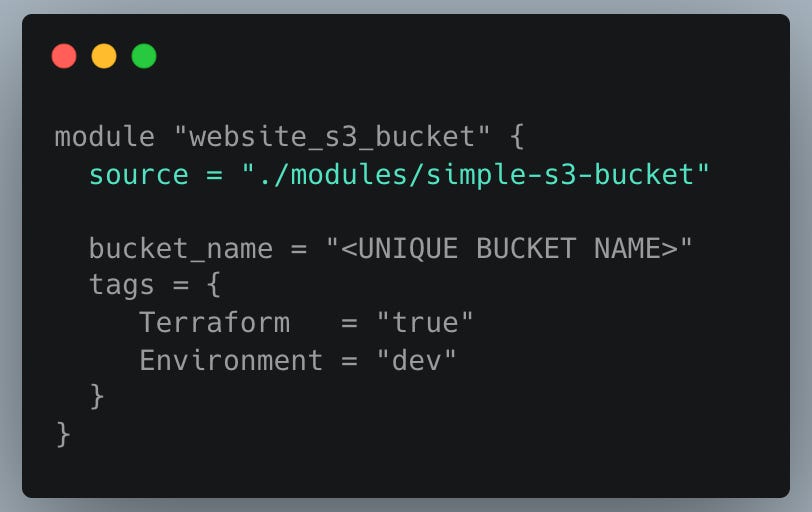
One thing that comes up occasionally (though not often discussed) is that the /modules folder doesn’t have to sit in the root of your repository.
If a some Terraform code is used only within a specific part of the infrastructure—say, GPU-enabled clusters or a particular client’s environment—it’s totally fine to keep it in a subfolder closer to where it’s used. And if you later realize the module is more broadly applicable, you can always move it up into the root /modules directory.
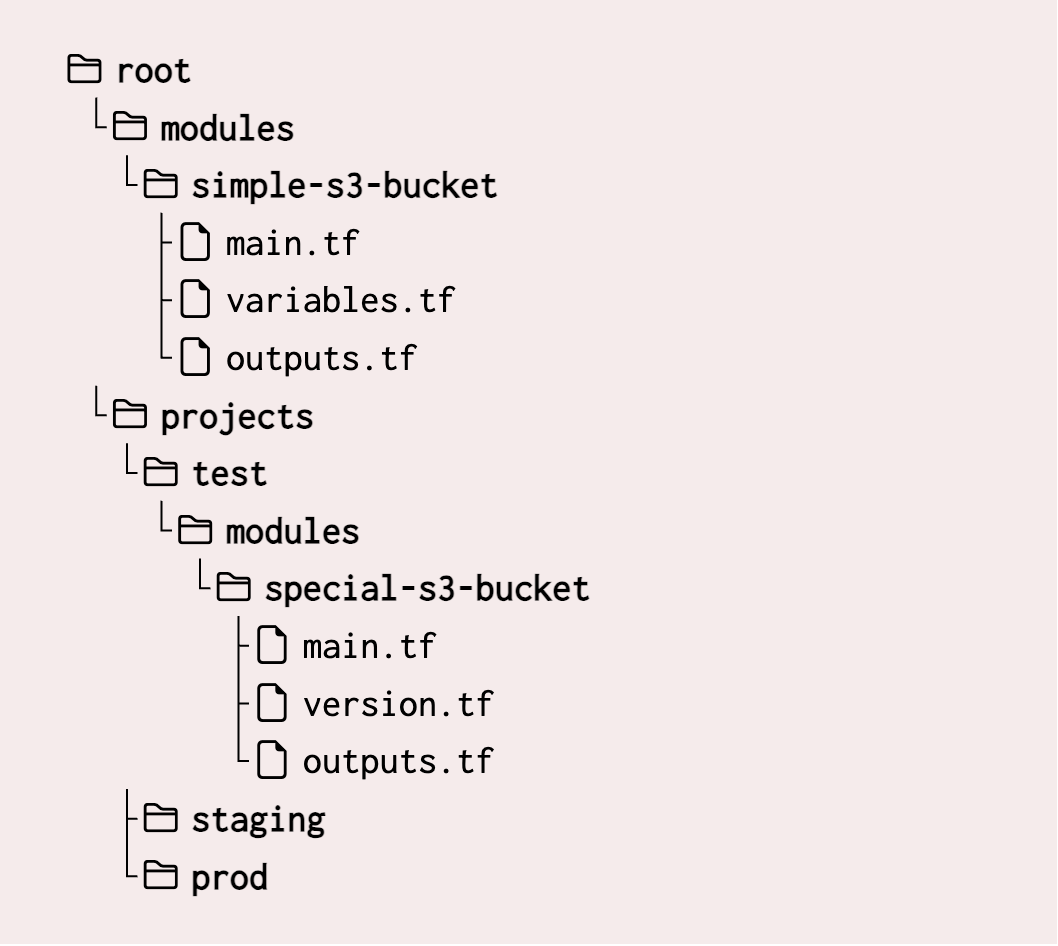
Now, if you want to take modules to the next level, consider this: put them in a separate repository.
Yep, you heard me.
I won’t go deep into the details here (that’s coming in a future post), but I’ll drop a teaser.
Imagine you have three environments—testing, staging, and production.
If your modules live in a dedicated repo, you can use Git refs (like tags or commit hashes) to pin specific versions of a module in each environment.
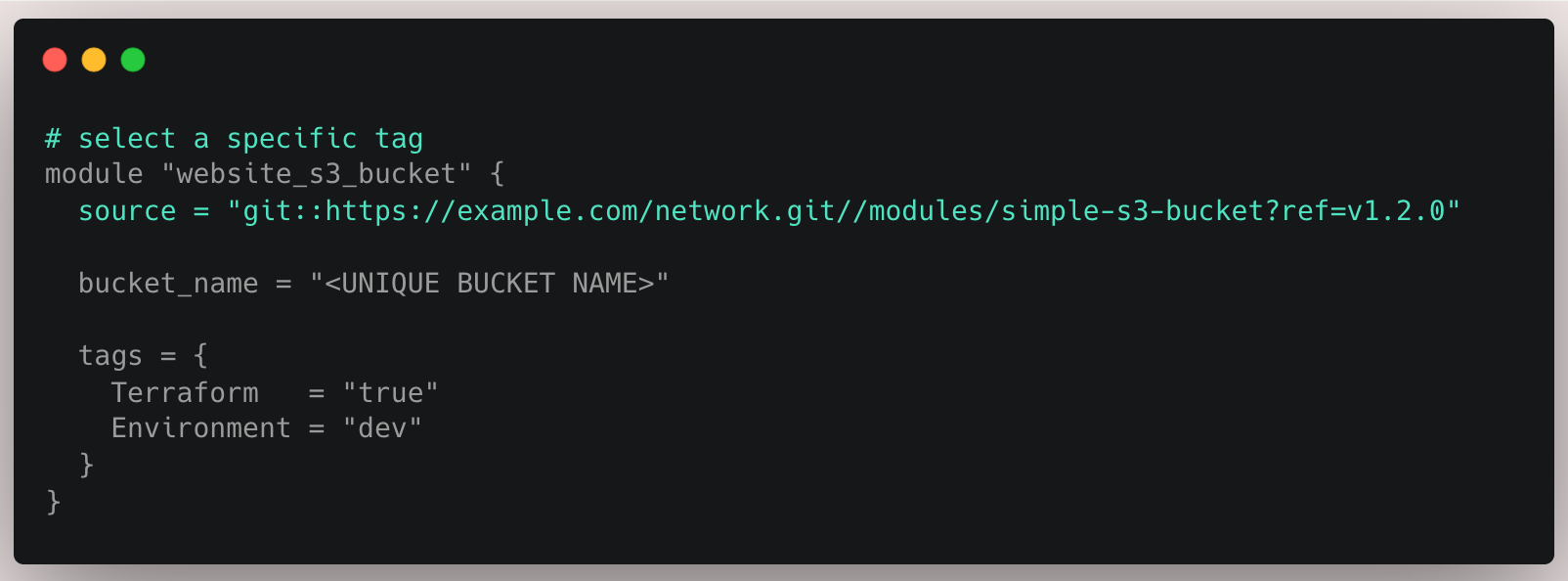
That means you can roll out a change to your module in just the testing environment, verify everything works, and then update the Git ref in staging and production only when you're confident it's safe.
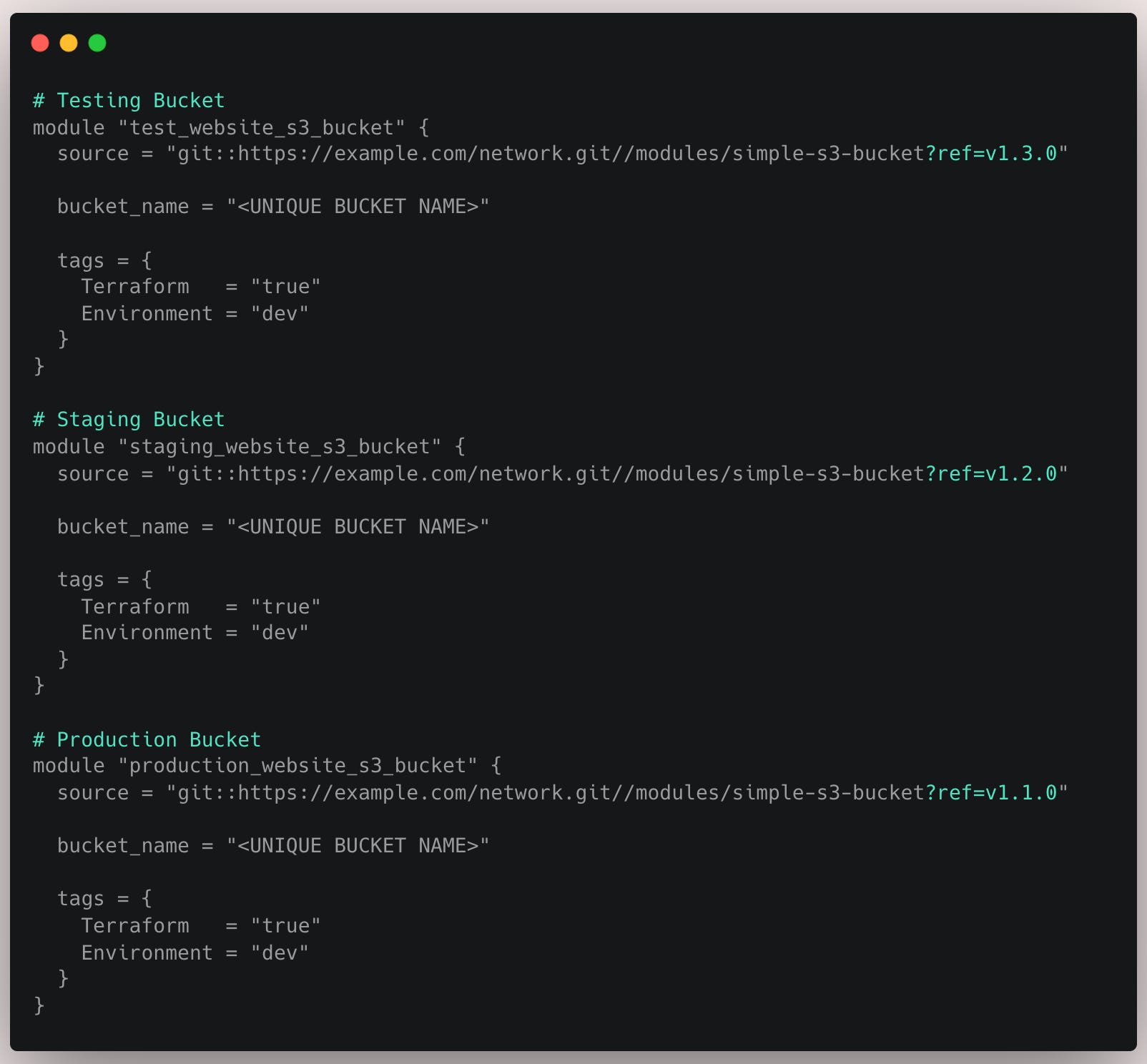
This approach gives you a much safer workflow and helps avoid accidental breaking changes in production.
Layout of Different Environments
Let’s say you have three environments: testing, staging, and production.
I prefer putting these environments under a common subdirectory named based on your cloud provider's logical boundaries—for example, /projects (for GCP), /accounts (for AWS), or /subscriptions (for Azure).
Now, according to the best practices, these environments should be as identical as possible. You’d ideally have automation in place to detect configuration drift and promote changes from testing → staging → production automatically after successful validation.
But the reality is usually more nuanced—especially when production is costly. There’s almost always some drift.
For example, your test environment likely won’t (and shouldn’t) mirror the full scale and consequently the cost of production.
Likewise, it rarely makes sense to block all other infrastructure changes behind a single pipeline that must propagate updates across every environment. In practice, different changes often move through environments at different times. As a result, your setups will inevitably diverge—and that’s okay.
So, for now, let’s focus on a single environment. How to best replicate production in testing is a topic I’ll leave to the reader.
And what is important—and often overlooked—is how you organize infrastructure code inside each environment.
The common but limiting approach
A common pattern I see is grouping resources of the same type in folders—like all IAM in one folder, all VPC networks in another, etc.
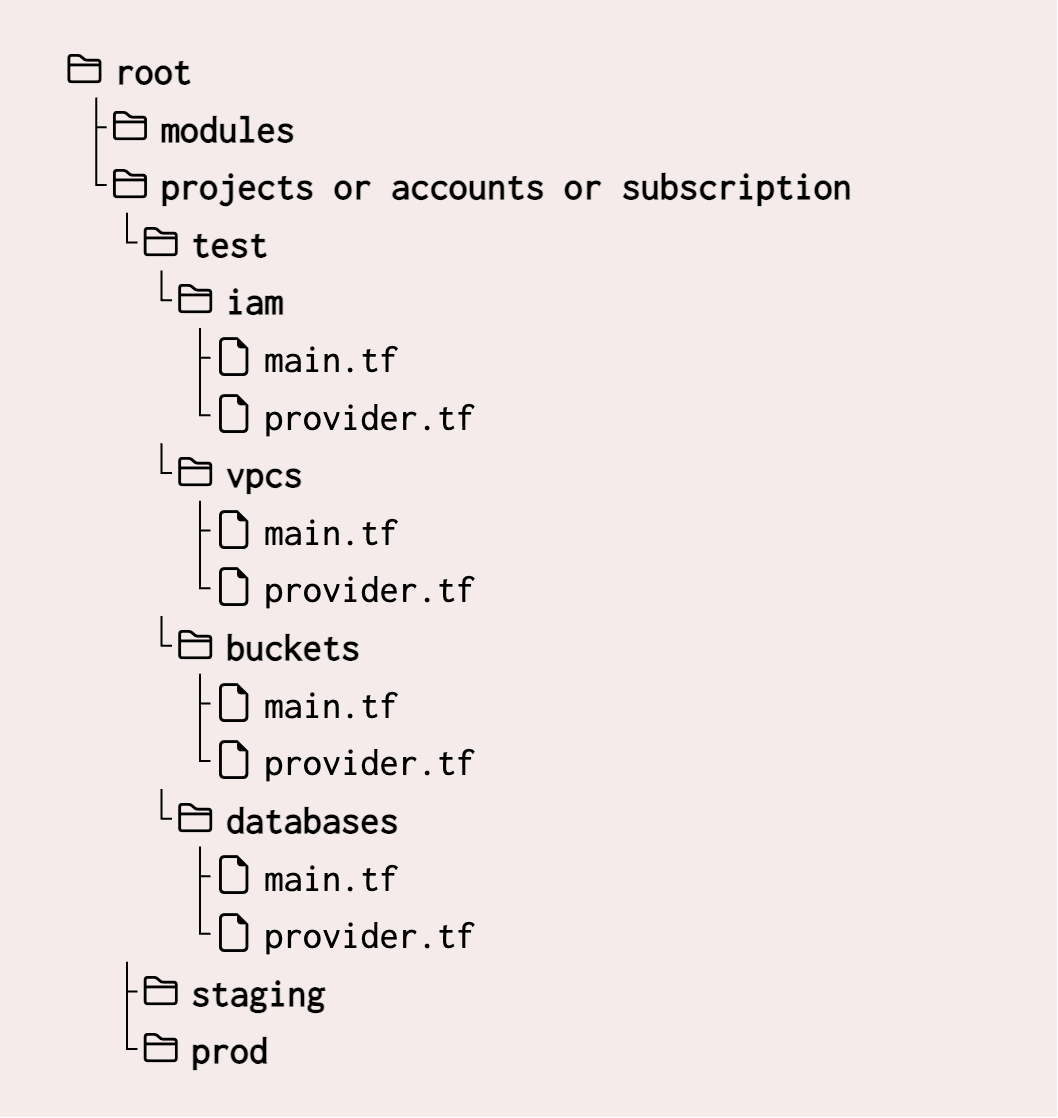
At first glance, this structure appears neat and logical — IAM permissions are managed at a single place, buckets are managed at a single place, basically everything is easy to locate, even as the number of resources grows.
But this approach actually doesn't scale well.
Every business hopes to grow without limits. As more developers join and more services spin up, each of those resource-type folders will grow too—with more IAM roles, more databases, more DNS records, and so on.
And as they grow, so does the time it takes to run terraform plan or terraform apply. It also becomes harder for automation tools to run them in parallel or safely.
So, what starts out looking like good layout quickly becomes a bottleneck.
The more scalable approach
A better structure is to organize resources by application, keeping everything related to a single app in one folder.
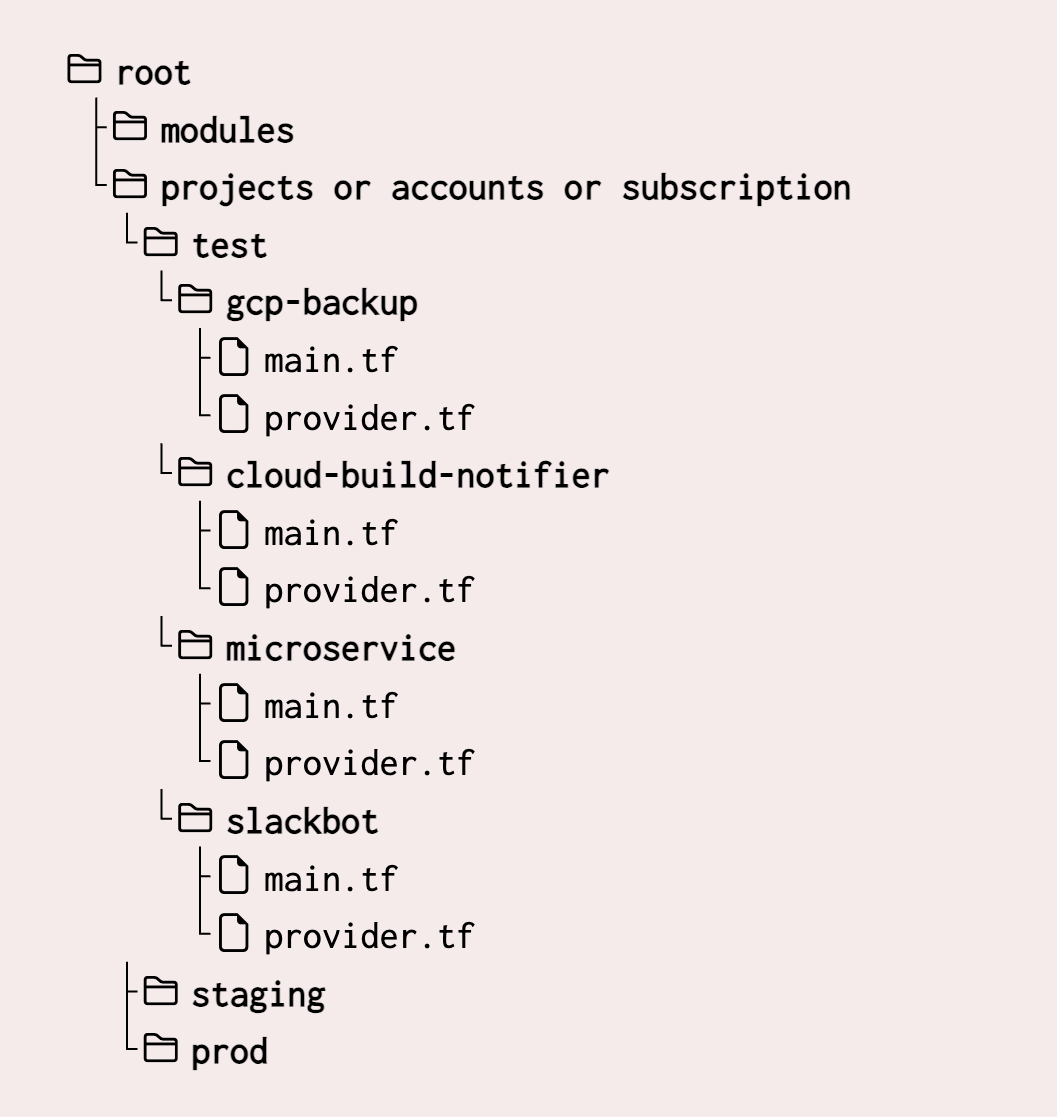
The application/folder names are chosen at random, but you get the idea.
Each application folder would contain everything it needs—IAM, DNS, storage, databases, etc.—and have its own Terraform state file.
This has a few benefits:
Smaller state files reduce the chances of locking issues and teams working on different infrastructure code don’t interfere with each other.
It mirrors how software is built and deployed—modular and self-contained.
Sure, your app-specific infra can grow too. But just like you’d refactor app code as it grows, you can also refactor the infra within that folder over time.

And that brings us to the next super useful concept.
Keeping the Terraform State In a Single Bucket
In a company with dozens of teams—some managing their own infrastructure code repositories—there’s often a shared belief: each team should have its own Storage Bucket for Terraform state files for security reasons.
But that’s really not necessary—it only adds complexity rather than solving anything.
With separate buckets, you now have more places to check when something breaks. You also need to manage all of those buckets—or delegate the responsibility to each team.
And while most engineers can write Terraform code, many struggle to configure or manage it properly.
For example, object versioning is often forgotten, and even when it is enabled, developers may roll back changes on their own—breaking the shared Terraform state in the process. Permissions are often overly broad, and backup automation tends to be scattered and inconsistent.
The good news is that you can store all Terraform state files in a single Storage Bucket. The key is how you organize and secure it.
The biggest reason teams resist this approach is access isolation. They don’t want their infrastructure to be visible or modifiable by others.
Luckily, GCP Storage Buckets support IAM-per-folder permissions. You can use Storage Bucket Managed Folders, and obviously give intuitive prefix to state files location names like <repository-name>/<path-to-folder-in-repo>/.
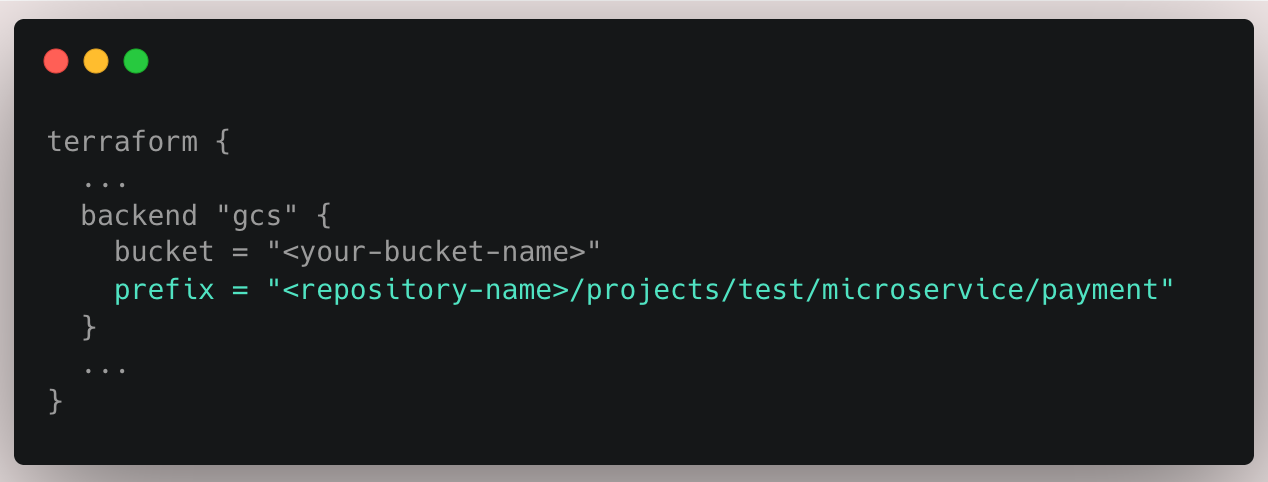
This approach allows you to control access at the storage bucket folder level — which maps to a folder in your VCS repository — using roles such as:
storage.objectViewer– read-only access to state filesstorage.objectUser– read/write access forterraform apply
Let’s say Team A manages the gcp-infrastructure repository. You’d give them storage.objectUser on the /gcp-infrastructure folder in the shared state bucket.
This means they can apply Terraform for all modules under that path—assuming they also have the required permissions to create actual GCP resources (like IAM service accounts, networks, etc.).
Or maybe you want tighter control. Suppose you only want them to run terraform plan locally, without the ability to apply changes. That’s possible too—with a bit more configuration work, depending on how your storage provider handles granular permissions.
This brings us to the last section.
Separate Cloud Provider — Separate Infrastructure Code Repository
This topic can get a bit subjective, because whether you keep infrastructure code for different cloud providers in separate repositories—or in a single one—depends heavily on how your automation is designed and what your company policies are.
Personally, I prefer to keep things separate: one repository for AWS, one for Azure, one for GCP, and so on.
Why?
Imagine your repo is wired up to Atlantis or some CI/CD system that deploys infrastructure to multiple clouds. Now ask yourself:
Are you okay with your CI/CD having full access and elevated permissions on all cloud providers? Or would you rather separate identities and restrict the blast radius in case the pipeline is hacked?
Are you comfortable with GCP-only developers being able to read and potentially modify AWS infrastructure code?
Are you okay with pushing complexity into your automation pipelines just to keep performance reasonable as the repo grows with more multi-cloud logic?
On the other hand, if you go with separate repositories per cloud provider, you'll face another set of trade-offs:
Are you okay managing developer access to multiple repositories?
Are you okay configuring and managing automation tools separately for each one?
Are you okay with cross-cloud resources being split between repositories? For example, GCP backups pushed to AWS S3—those kinds of interactions will still happen.
Some of these questions are more important than others, and some opinions may be stronger depending on your context. But in the end, what matters is reaching a team-wide consensus that fits your tooling, scale, and security model.
⏪ Did you miss the previous issues? I'm sure you wouldn't, but JUST in case:


I hope you find these resources useful. Stay tuned for more exciting developments and updates in the world of cloud infrastructure in next week's newsletter.
Until then, keep ☁️-ing!
Warm regards, Teodor